Share:
Many of us work with databases occasionally or daily. And I bet all of us are being told that to speed up the query speed, we can create and use index for tables. But probably few of us know how index is actually implemented under the hood, myself included. So I started developing an interest in this topic a while ago and wanted to know, at least at a high level, what makes database indexing happens.
Later on, after I did some research, and found out that the core of the database index is implemented using the well-known data structure - B+ tree (MySql as an example). In this blog, we will do brief diving into the B+ tree, and see why it is chosen to implement index over other data structures.
Background
Before we jump straight into B+ tree, let's first refresh our memory on how hard disk handles I/O, because it is crucial to understand it for why databases choose B+ tree to implement indexing.
When disk tries to read data, the read head has to first locate where the data is stored, the data-seeking process involves moving the head of the mechanical arm to the top of block where data gets stored. And we all know that this seeking process is time-consuming, due to this, disk read can be thousands of times slower than RAM read. This also leads to the difference in how data gets read after it is located. Because RAM is so fast, we often ignore the time of data access within it, so the data read in RAM is fetching on demand. While in disk, since it's hundreds or thousands times slower than RAM, so in order to improve the efficiency and to reduce time, every time, it will pre-fetch data, even though we only need 1 byte of data, it will prefetch the entire block of data starting at the address of that 1 byte of data.
This is based on the Spatial Locality in computer science, that is,

If a particular storage location is referenced at a particular time, then it is likely that nearby memory locations will be referenced in the near future.
The image below depicts a high-level view of a hard disk.
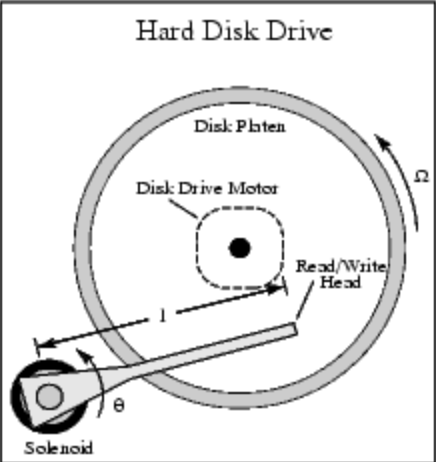
And also I found this video on Youtube which shows how hard disk performs I/O operations. Notice how the mechanical arm is moving.
So for programs with a high spatial locality, pre-fetching could improve their I/O efficiency.
B+ Tree
Now, we can start the talk of B+ tree. I assume you are somewhat familiar with B tree, since B+ tree is a variant of B tree with a few differences. The differences in B+ tree are that,
- Internal node doesn't store data
- Leaf node doesn't store children pointers, only store data
- Leaf node is connected to each other through a pointer to next leaf node
Below is a simple picture showing the differences of B/B+ trees:
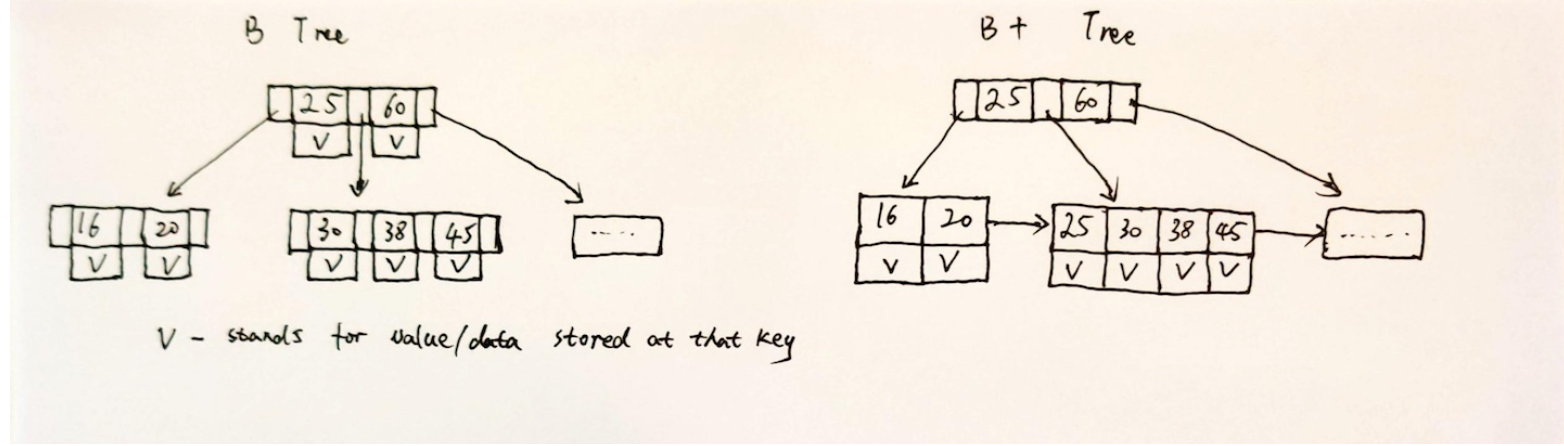
(In case the text in the picture is hard to read, V in the picture stands for the value/data stored at that key entry)
A conceptual definition of B+ tree's leaf & internal nodes looks like below:
typedef struct {
array<Key> keys;
array <Value> values;
BlockPtr next;
} Leaf;
typedef struct {
array<Key> keys;
array<BlockPtr> children;
} Node;
The Block in the abstract definition above reflects the block in the disk, which further reflects the pre-fetching of disk I/O, that is, each node reading will fetch a block of data into RAM, and the RAM representation of block is Page managed by operating system.
Note that, for B/B+ tree, the time complexity for searching a key is O(logdN), d is the degree of B/B+ tree and N is the number of keys. Also, note that each leaf is connected through a pointer, the reason for this is to improve range access, say, if we want to get data within range [20, 45], once we locate key 18, we can just read data from that point on and keep going through leaf through the pointer to get next range of data up to 45, compared to B tree, this has better efficiency.
Why B+ Tree
You might wonder why B+ tree is chosen, but not others, such as red-black tree, which is also a highly efficient search tree.
We know that index itself is also very large, especially nowadays, data stored in the database is often huge, which results in the index also to be huge that it cannot be stored in memory completely. As a result, index is often stored in the disk as a file, this will make the indexing process trigger disk I/O. As discussed above, disk I/O is hundreds or thousands times slower than memory access, so the performance of indexing is bounded by the number of times doing disk I/O, the less the better.
Based on this, let's take a look at red-black tree again, if index data is huge, then the height of it will be very deep, much deeper than B+ tree's height (in reality, degree of B+ tree, d is often a large integer, > 100), in addition, the nodes logically close to each other doesn't mean physically close. These will make indexing using red-black tree involving much more disk I/O than B+ tree.
Now you see the shining part of B+ tree, by making degree d large (> 100) reduces the height of tree, which further reduce disk I/O for each node access, then by making size of each node to be size of a block (page), each disk read can make sure the entire node's data fit into a page, also, due to that each node often stores a large amount of keys compared to red-black tree's node, the search of key within page can be done using binary search, which is also fast & efficient.
To Be continued
Up until now, I hope you get an overall high-level understanding of B+ tree, and why it is efficient & chosen to be used for database index implementation. We will talk about the usage of B+ tree for implementing index in database (MySQL) over the next blog.



